
私達は「アニマトロニック・ヒューマノイドロボット・プロジェクト」という題目で,新エネルギー・産業技術総合開発機構(NEDO)による平成16年度21世紀ロボットチャレンジプログラム「次世代ロボット実用化プロジェクト」に参加し,その成果を2005年6月9日から19日までの11日間,愛・地球博のイベントプロトタイプロボット展で発表しました. こちらで紹介されています. ここではその技術について簡単に解説します.
ヒューマノイドロボット運動の研究は,歩行・匍匐・起き上がりといった個々の「動作」を対象とする段階から,様々な動作を統合し人間のように生き生きとした「行動」を実現する「アニマトロニクス」展開の段階へと移りつつあります.
ヒューマノイドの運動制御は,数十の関節を操り,衝突・接触などのダイナミックな力学現象を活用して外乱に富んだ環境内を自在に動き回らせるという,ロボット制御の問題としては極めて難しい部類に属するものです. 加えて「動作」を「行動」へと進化させる上では,そのような身体制御系と,さらに一段階上の知的な情報処理活動とを双方向に結びつけることが求められます. アニマトロニクスは,これらの別個に見てもいまだチャレンジングな技術の融合の末に達成されると言えるでしょう.
本プロジェクトは,萌芽的試みではありますが,
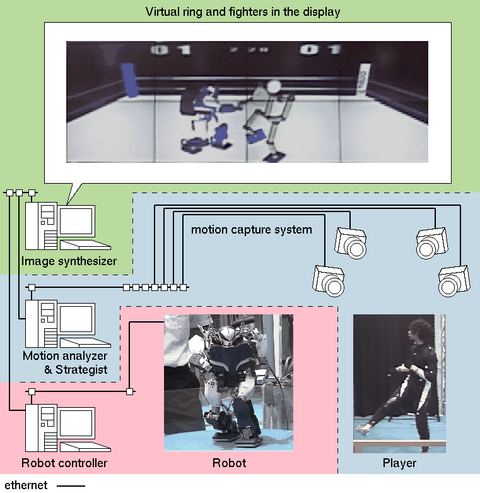
上図に示すように,システム全体は 1) 行動解析&意志決定部 2) ロボット制御部, 3) 画像合成部 の3つのパートから成ります.
ロボットとプレイヤ(人間)は物理的な直接攻撃を加え合うのではなく,互いにある距離を持って離れた場所で対峙します. プレイヤの運動をフィールド内に配置されたカメラによるモーションキャプチャシステムを用いて計測し,後述するミメティックコミュニケーションモデルに基づいてリアルタイムに行動を認識,ロボットの戦略を決定します. これを行なうのが1) 行動解析&意志決定部であり,決定された戦略に対応する運動の指令値は2) ロボット制御部に送信されます. この指令値は運動の"見た目"の情報しか含まず,物理法則に矛盾する可能性があります. これを,オンライン運動計画を用いて物理法則を満足するように修正し,ロボットへの制御入力とします. その結果生成されたロボットの運動情報と,計測されたプレイヤの運動情報とを受けとり仮想リング上に再構成するのが3) 画像合成部です.
試合は合成された画像上で進行します. 互いの攻撃判定は,各々を再現した仮想キャラクター同士の幾何干渉演算によってなされ(本物のプレイヤやロボットに打撃が伝達されるわけではありません),制限時間内により多くの攻撃をヒットさせることが直接の目的となります.
モーションキャプチャシステムには,Motion Analysis社製MAC3Dシステムを採用しました. 天井に配置された10個のカメラがロボットの眼となって,プレイヤの着るスーツに取り付けられた再帰性反射マーカの3次元位置を計測します. 全観測点は,同システムに付属のソフトウェアによってラベリングまでなされた後,我々の開発した高速逆運動学アルゴリズムを適用することによってリアルタイムに関節角情報へと変換されます. この手続きにより,プレイヤの運動パターンを関節角シーケンスとして認識することが可能になります.



Donaldによって提唱されたミメシス理論は,他者行動の模倣,すなわち認識と自分自身の身体による再現というプロセスの繰り返しによって,行動を記号化し,また逆に記号化された行動を想起する知能メカニズムが獲得されていくとするものです. 我々はこれをヒントとし,モーションキャプチャによる計測結果からの運動の記号化と,記号からロボットにより再現される運動軌道への変換という双方向の情報処理を,隠れマルコフモデル(HMM)を用いた統計的手法によって行なうミメシスループというフレームワークをこれまでに提案してきました.
従来このミメシスループが扱うのは,ロボット一体の運動に関する情報のみでしたが,これを拡張しループを階層的につなぎ合わせることで,複数の人間のインタラクションパターンを学習するメカニズムを新たに開発しました. さらにこれは,学習したインタラクションパターンに基づいて,他者の現在の行動を反映しロボットが自身の行動戦略を選択する,オンライン意志決定機構としての機能も持っています. これにより,原始的ではありますが人間とロボットの間のコミュニケーションを発現する知能に相当する部分が作られます.
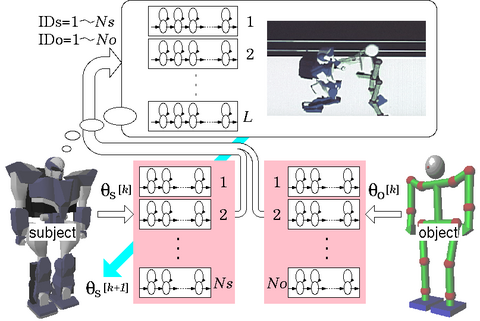
バーチャルファイトにおいては,あらかじめ格闘している二人の人間(いわば格闘術の先生)の様子を同時に観察し,例えば「右ストレートを出されたら右にかわす.その直後に相手は腕を元に戻す動作をとるであろう.その間を利用して反撃を繰り出す」などという複雑なパターンをデータベースに蓄積しておきます. もちろんこのようなロジカルな戦略としてではなく,要素動作の組み合わせシーケンスとしてパターンが記憶されます. この蓄積されたデータを元に,実際の戦いの場面でプレイヤが右ストレートを出してきたときにロボットがどのように行動するかなど,その意志決定がなされることになります.
前節の意志決定機構は, 運動指令として30[ms]置きのロボットの姿勢および支持状態シーケンスを 出力します. しかしながらそれらの出力は時間的にも空間的にも粗く, また運動の"見た目"の情報しか含まず物理法則に矛盾する可能性があります. すなわちヒューマノイドロボットは地面に機械的に結合しているわけでは ないために,引張方向に力を発生できないという厳しい制約が課されますが, これを満足しないような実現不可能な運動を指令され得るということです. これを,物理法則を考慮して実際のロボットに適用可能な形に再構成し, ロボットへの直接の制御入力とするのがオンライン運動計画です. これまでに,物理法則を考慮しない運動パターンを修正・変換し ロボットに適用するためのテクニックは幾つか提案されていますが, それらのいずれもオフラインによるものでした.
開発した方法は, 次々に送られてくる指令値シーケンスを蓄えていき, 支持状態の指令が変わった時点で, 変わる直前までの一連の指令値セグメントから 運動を表現する連続関数のセットを計算するものです. この関数セットには,両腕の姿勢・両足先の位置姿勢・重心の位置・胴体の姿勢 を表すものが含まれます. 原理的に接地状態が切り替わるまでの時間 (平均数百ミリ秒程度)に相当する遅延が生じるという問題はありますが, 再構成を開始した時点でのロボットの状態を各セグメントの初期状態に 反映し,完全にオンラインで機能します. 運動指令は連続関数として出力されるので, ロボットの制御周期は自由に(元の姿勢シーケンスの時間間隔と無関係に) 選べるという利点を持ちます.
UT-μ2についてはこちらのページをご参照下さい.
UT-μ2運動実験(MPEG,14MB)
愛・地球博でのステージデモ風景(MOV,53MB,QuickTimeなどを御利用下さい)
画面上に合成された格闘(MPEG,2.0MB)
バーチャルファイトの様子(MPEG,8.9MB)
バーチャルファイト再現(MPEG,3.7MB)
統括: 中村仁彦
演出: 山根克
メカデザイン: 山本江 杉原知道
プログラミング: 杉原知道 高野渉 山根克
アシスタント: 大石理也 大川和宏
出演: 青野達人(Sticky the Barbarian) 山本江(レフェリー) 中村仁彦(Dr.ナカムラ)
UT-μ2(magnum the Darkside)
演技: 高野渉 青野達人 鈴木秀治
協力: 株式会社ナックイメージテクノロジー
Motion Analysis Corporation
Special Thanks: EDGEWEAR(BGM提供) 諏訪和美(デモMC)
and all YNL members
